The (Codex) Agent Loop
https://openai.com/index/unrolling-the-codex-agent-loop/
Commonality between all AI agents (Cursor, Codex, Claude, Gemini, etc.) is that they're all really big event loops:
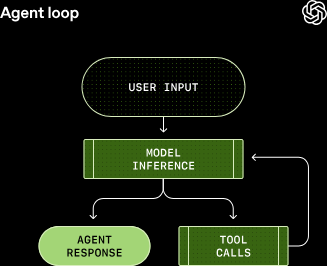
The user's input initially goes to the agent where it's prepared for the LLM under the covers. The input going to the LLM is known as a prompt.
The time the LLM spends processing the prompt is known as inference. The inference process starts out by translating the human-readable prompt into LLM-readable input tokens. These tokens are integers that index into the model's vocabulary: remember, LLMs are powered by matrices (linear algebra) and those integers allow the LLM to access its matrices and "read". The process of translating a prompt into tokens is known as tokenizing.
Once the LLM acts on the tokenized prompt, it either produces a response to the input or requests a tool call; a CLI program, an API, etc. that the LLM can reach out to and use to act on the user's input.
This is the "agent loop" - get input from the user, tokenize it for the LLM, have the LLM process it, and send a response back to the user. The response can either be a completed instruction or a follow-up question, and Codex defines these responses as "assistant messages". Other agents likely have their own concept of assistant messages.
Assistant messages represent a termination state in the agent loop: the LLM has completed the work asked of it and it's now up to the user to make another request.
These interactions are referred to as conversation, and each singular interaction is referred to as one turn of conversation. Codex specifically uses the terminology "thread" for conversations.
Directly from the article:
Every time you send a new message to an existing conversation, the conversation history is included as part of the prompt for the new turn, which includes the messages and tool calls from previous turns:
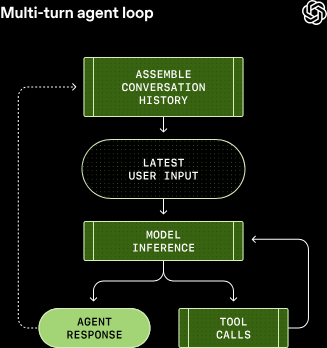
Now you've got a whole conversation going with a LLM because it's caching your prior messages as additions to the initial prompt. The length of the prompt matters since every LLM has a context window, which is the maximum number of tokens the LLM can hold in a single inference process.
The devil in the details here is that the contex window's length includes both input (what the LLM gets) AND output (what the LLM sends back) tokens. What varies between agents (i.e., Codex) is their ability to manage the context window.
This may not be exactly how all the agents do it, but Codex sends HTTP requests to LLMs via OpenAI's Responses API. Other AI companies seem to be doing something similar where their HTTP payloads pass along three pieces of data:
- instructions: a message from either the system or developer meant to be inserted into the LLM's context; this is usually the "you are a [x]" that guides the LLM to have a "personality" or focus
- tools: a list of services (local tools, APIs, etc) that the LLM can access
- input: the prompt from the end user; usually text, but can also be files or images